
Most of the times, results coming from a research project – specifically in the health sciences field – use statistical significance to show differences or associations among groups in the variables of interest. Setting up the null hypothesis as no difference between groups and the alternative showing just the opposite –i.e, there is a relationship between the analyzed factors –, and after performing the required statistical method, a p-value is provided. This p-value indicates, under an established threshold of significance (say, Type I or alpha error), the strength of the evidence against the null hypothesis. If the p-value is lower than alpha, results lead to a statistically significant conclusion; otherwise, there is no statistical significance.
According to my personal and other biostatisticians’ experience in the medical area, most of physicians are only interested in the statistical significance of their main objectives. They only want to know whether the p-value is below alpha. But, the p-value, as noted in the previous paragraph, gives limited information: essentially, significance versus no significance and it does not show how important the result of the statistical analysis is. Besides from significance, confidence intervals (CI) and measures of effect sizes (i.e., the magnitude of the change) should be also included in the research findings, as they can provide more information regarding the magnitude of the relationship of the studied variables (e.g., changes after an intervention, differences between groups,…). For instance, CIs facilitate the range of values within the true difference value of the studied parameter lies.
In clinical research is not only important to assess the significance of the differences between the evaluated groups but also it is recommended, if possible, to measure how meaningful the outcome is (for instance, to evaluate the effectiveness and efficacy of an intervention). Statistical significance does not provide information about the effect size or the clinical relevance. Because of that, researchers often misinterpret statistically significance as clinical one. On one hand, a large sample size study may have a statistically significant result but a small effect size. Outcomes with small p-values are often misunderstood as having strong effect sizes. On the other hand, another misinterpretation is present when non statistical significant difference could lead to a large effect size but a small sample may not have enough power to reveal that effect.
Some methods to determine clinical relevance have been developed: Cohen’s effect size, the minimal important difference (MID) and so on. In this post I will show how to calculate Cohen’s effect size (ES) [1], which is the easiest one.
ES provides information regarding the magnitude of the association between variables as well as the size of the difference of the groups. To compute ES, two mean scores (one from each group) and the pooled standard deviation of the groups are needed. The mathematical expression is the following:
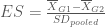
where 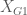
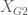
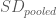

being 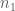
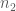
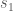
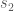
But, how can it be interpreted? Firstly, it can be understood as an index of clinical relevance. The larger the effect size, the larger the difference between groups and the larger the clinical relevance of the results. As it is a quantitative value, ES can be described as small, medium and large effect size using the cut-off values of 0.2, 0.5 and 0.80.
Clinical relevance is commonly assessed as a result of an intervention. Nevertheless, it can be also extended to any other non experimental study design types, for instance, for cross-sectional studies.
To sum up, both significances (statistical and clinical) are not mutually exclusive but complementary in reporting results of clinical research. Researchers should abandon the only use of the p-value interpretation. Here you have a starting point for the evaluation of the clinical relevance.
[1] Cohen J. The concepts of power analysis. In: Cohen J. editor: Statistical power analysis for the behavioral sciences. Hillsdale, New Jersey: Academic Press, Inc: 1998. p. 1-17.


