

Ipek Guler is an intern at Biostatech, Advice, Training and Innovation in Biostatistics, S.L. She has a MSc in Statistical Techniques from the University of Santiago de Compostela (Spain) and a BSc in Statistics from Gazi University (Turkey).
In previous posts about longitudinal data by Urko Agirre and Hèctor Perpiñán, mentions have already been made to the Mixed Models methodology .
Usually in medical and biological studies, the designed experiments include repeated measures which are used to investigate changes during a period of time repeatedly for each subject in the study. Multiple measurements are obtained for each individual at different times. These type of longitudinal data can be analyzed with a mixed effects model (Pinheiro and Bates, 2000) which allows modeling and analysis of between and within individual variation. An example of such data can be growth curves measured over time.
In many practical situations, using traditional parametric regression techniques is not appropriate to model such curves. Misleading conclusions may be reached if the time effect is incorrectly specified.
Durban et al, (2005) presented flexible mixed models for fitting subject specific curves and factor by curve interactions for longitudinal data in which the individual and interaction curves are modeled as penalized-splines (P-splines) and model’s estimation is based on the mixed model representation of P-splines (Currie and Durban, 2002).
This representation is quite interesting because it allows us to use the methodology and the several software available for mixed models (e.g., nlme and lme4 packages in R), and it also comes equipped with an automatic smoothing parameter choice that corresponds to maximum likelihood (ML) and/or restricted maximum likelihood (REML) estimation of variance components. With this representation, the smoothing parameter becomes the ratio between the variance of residuals and the variance of the random effects.
First of all, let`s define a linear mixed model for a longitudinal data.
As a matrix notation;

is the vector of the observed responses ,

is the fixed effects parameters vector,
-
is the residual vector,
-
denotes unknown individual effects.
a known designed matrix linking
to
![X=\left[\begin{array}{cc}X_{1}\\X_{2}\\\vdots\\ X_{N}\end{array}\right]](https://s0.wp.com/latex.php?latex=X%3D%5Cleft%5B%5Cbegin%7Barray%7D%7Bcc%7DX_%7B1%7D%5C%5CX_%7B2%7D%5C%5C%5Cvdots%5C%5C+X_%7BN%7D%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
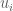
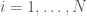

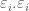
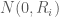
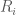

Consider a flexible regression model,
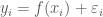

Where 
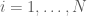
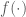

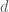
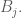
And we reformulate it as;
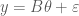
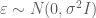
Depending on the basis that is used for the P-splines, 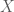

- Truncated polynomials
![X=\left[1,x,\ldots,x^p\right]](https://s0.wp.com/latex.php?latex=X%3D%5Cleft%5B1%2Cx%2C%5Cldots%2Cx%5Ep%5Cright%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
![Z=\left[(x_{i}-\kappa _{k})^p_+\right]](https://s0.wp.com/latex.php?latex=Z%3D%5Cleft%5B%28x_%7Bi%7D-%5Ckappa+_%7Bk%7D%29%5Ep_%2B%5Cright%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)
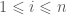

- B-splines
![X=[1:x]](https://s0.wp.com/latex.php?latex=X%3D%5B1%3Ax%5D&bg=ffffff&fg=4c4c4c&s=0&c=20201002)

Where 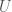
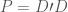

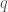
Therefore the model becomes;

and
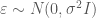
Where 
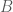

With this mixed model representation of P-splines, we can obtain more flexible mixed models which allows us to have a simple implementation of otherwise complicated models. In future posts, we can talk more about these flexible models with individual curves and factor by curve interactions also described in Durban et al (2005).





